On December 13, 2021, the third session of the "Time·Frontier" Seminar of the School of Computer Science and Technology invited Viktor K. Prasanna, a famous professor from the University of Southern California, to talk about "Accelerating Graph Neural Networks".Many teachers, students, experts, and scholars listened to the presentation and had a heated discussion via Zoom online conference.

Graph neural network (GNN) is widely used in the field of machine learning, but the computing overhead restricts the scalability of GNN. Professor Viktor introduced the development status and application of GNN and analyzed the challenges faced by GNN acceleration such as data scale, data reuse, random memory access, load inequality, and heterogeneous kernel. In response to these problems, Professor Viktor focused on two breakthrough research results, which are of great significance for the optimization of downstream application performance.
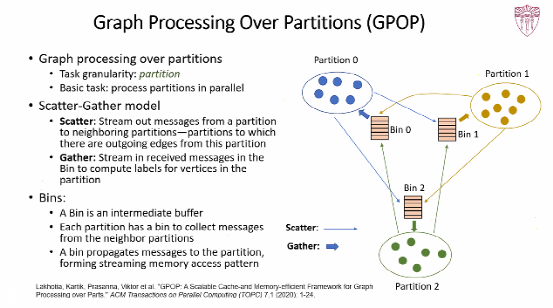
The first research result introduced by Professor Viktor was Graph Processing Over Partitions(GPOP), which mainly accelerated the image processing stage and divided the image into small-grained sub-charts for parallel processing to improve the performance. By using the Scatter-Gather parallel calculation model, GPOP includes two stages: Scatter and Gather. In the Scatter phase, stream out messages from a partition to neighboring partitions, and in the Gather phase, stream in received messages in the Bin to compute labels for vertices in the partition. At the same time, GPOP is designed in a stream memory access pattern, using the Bin as an intermediate buffer to speed up graph computation by processing each partition and multiple iterations in parallel.

The second research result is to accelerate the sampling-based GNN computing (HP-GNN) by using the CPU+FPGA platform. Given GNN parameters and CPU+FPGA platform metadata, HP-GNN can accelerate the training of various sampling-based GNN models through hardware kernel optimization. HP-GNN system architecture consists of three parts: parallel computation kernels, update kernels, and aggregate kernels. The parallel computation kernels are distributed to multiple dies. These dies and multiple DDRs and FPGA chips are connected through an all-to-all interconnection. The updated kernel performs multiplication-accumulation operations in each clock cycle. Then the aggregate kernel uses the self-defined Scatter-Gather paradigm for data reuse and aggregation operations, and finally outputs the results to the host program. At the same time, HP-GNN designed a friendly API to shield the hardware architecture, through which users can easily use the CPU+FPGA platform to accelerate GNN model training.
Viktor K. Prasanna is a professor of Electrical Engineering and Computer Science at the University of Southern California, director of the Energy Information Center, and ACM/IEEE/AAAS Fellow. He has conducted research in the areas of high-performance computing, parallel and distributed systems, cloud computing, and intelligent energy systems. Professor Viktor has long served as co-chair of the Steering Committees of the International Parallel & Distributed Processing Symposium(IPDPS) and the International Conference on High-Performance Computing (HiPC). He is the founding Chair of the IEEE(Institute of Electrical and Electronics Engineers)Computer Society's Parallel Processing Technical Committee and currently serves as Editor-in-Chief of the Journal of Parallel and Distributed Computing (JPDC). Professor Viktor received the Distinguished Service Award from the IEEE Computer Society in 2010, and the W. Wallace McDowell Award in 2015. What's more, he has received Best Paper Awards at several international conferences and journals, including ACM Computing Frontiers (CF), IEEE IPDPS, ACM/SIGDA International Symposium on Field Programmable Gate Arrays, and International Conference on Parallel and Distributed Systems (ICPAD).


